Redis 6.2 原理学习
前置知识:C 语言、数据结构、操作系统、计网、网络编程与网络模型。
1. 预备知识
1.1 学习源码的过程
了解项目的背景
这相当于了解了项目的需求。为什么要有这个源码?充分了解项目的功能,并熟练使用
将“逆推”转化为“正向推导+验证”是阅读源码的重要方法。了解项目的功能是这一方法的基础。调试代码
通过断点调试,掌握代码的流程走向、主次关系和依赖关系。划分源码
根据每个包或模块的功能,将源码划分为几个部分。由底层到上层,逐个击破
先阅读不依赖或较少依赖其他模块的基础模块,然后逐步上移,完成整个项目源码的阅读。修改并调试源码
在由底层到上层阅读完成后,横向以功能点为维度串联源码的实现逻辑。
1.2 Redis 源码编译
1.2.1 拉取 Redis 源码
在 Linux 上 git clone 源码,并切换到熟悉的版本分支(如 6.2)
选用一种合适的方式在终端或文本编辑器查看。我使用的是 CLion + WSL2
Redis 官网提供的安装包版本有 6.2 (2021年发布)、7.0(2022年发布)、stable 三个版本。

截止2025年1月6日,Redis的最新发行版是 7.4.2 。
1.2.2 Redis 项目结构概述
Redis 6.2 的项目结构主要包含以下目录和文件:
src/核心源代码:包含 Redis 的核心实现,如
server.c(主服务器逻辑)、networking.c(网络处理)、db.c(数据库操作)等。数据结构:如
dict.c(字典)、sds.c(简单动态字符串)、ziplist.c(压缩列表)等。命令实现:如
t_string.c(字符串命令)、t_list.c(列表命令)等。持久化:如
rdb.c(RDB 持久化)、aof.c(AOF 持久化)。集群:如
cluster.c(集群管理)。模块系统:如
module.c(模块支持)。
tests/单元测试:包含 Redis 的单元测试代码,用于验证各个功能模块的正确性。
deps/依赖库:包含 Redis 依赖的第三方库,如
jemalloc(内存分配)、hiredis(C 客户端库)、linenoise(命令行编辑库)等。
utils/实用工具:包含一些辅助工具,如
redis-benchmark(性能测试工具)、redis-check-aof(AOF 文件检查工具)等。
redis.conf配置文件:Redis 的默认配置文件,包含各种配置选项。
Makefile构建文件:用于编译和安装 Redis。
README.md项目说明:提供 Redis 的基本信息、构建和运行指南。
CONTRIBUTING.md贡献指南:说明如何为 Redis 项目贡献代码。
COPYING许可证文件:Redis 使用 BSD 3-Clause 许可证。
1.2.3 编译二进制文件
首先关闭正在运行的 redis-server,可以用 systemctl stop 关闭服务,或者通过 netstat 端口号找到进程号再通过 kill -9 杀进程。
在
/src目录下执行命令:make MALLOC=libc CFLAGS="-O0"注意要关闭编译优化。
之后就可以看到一堆 .o 和 redis-server二进制文件了。
1.3 GDB 初步使用
1.3.1 启动 Redis 服务器并加载 GDB
打开终端,输入命令
gdb redis-server启动 GDB 调试器,并加载 redis-server 程序。dogitry@LAPTOP-M3IADGND:~/code_study/redis/src$ gdb redis-serverGDB 启动后会显示版本信息、版权声明等,此时输入
r命令,开始运行 redis-server 程序。GNU gdb (Ubuntu 12.1-0ubuntu1~22.04) 12.1 Copyright (C) 2022 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty" for details. This GDB was configured as "x86_64-linux-gnu". Type "show configuration" for configuration details. For bug reporting instructions, please see: <https://www.gnu.org/software/gdb/bugs/>. Find the GDB manual and other documentation resources online at: <http://www.gnu.org/software/gdb/documentation/>. For help, type "help". Type "apropos word" to search for commands related to "word"... Reading symbols from redis-server... (gdb) r程序运行过程中,会输出 Redis 启动的日志信息,如版本号、运行模式、端口号等。
(gdb) r Starting program: /home/dogitry/code_study/redis/src/redis-server [Thread debugging using libthread_db enabled] Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1". 120760:C 11 Jan 2025 17:43:13.087 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo 120760:C 11 Jan 2025 17:43:13.087 # Redis version=6.2.17, bits=64, commit=441001a4, modified=0, pid=120760, just started 120760:C 11 Jan 2025 17:43:13.087 # Warning: no config file specified, using the default config. In order to specify a config file use /home/dogitry/code_study/redis/src/redis-server /path/to/redis.conf 120760:M 11 Jan 2025 17:43:13.089 * monotonic clock: POSIX clock_gettime _._ _.-``__ ''-._ _.-`` `. `_. ''-._ Redis 6.2.17 (441001a4/0) 64 bit .-`` .-```. ```\/ _.,_ ''-._ ( ' , .-` | `, ) Running in standalone mode |`-._`-...-` __...-.``-._|'` _.-'| Port: 6379 | `-._ `._ / _.-' | PID: 120760 `-._ `-._ `-./ _.-' _.-' |`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | https://redis.io `-._ `-._`-.__.-'_.-' _.-' |`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | `-._ `-._`-.__.-'_.-' _.-' `-._ `-.__.-' _.-' `-._ _.-' `-.__.-' 120760:M 11 Jan 2025 17:43:13.092 # Server initialized 120760:M 11 Jan 2025 17:43:13.093 # WARNING Memory overcommit must be enabled! Without it, a background save or replication may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect. [New Thread 0x7ffff76b4640 (LWP 120764)] [New Thread 0x7ffff6eb3640 (LWP 120765)] [New Thread 0x7ffff66b2640 (LWP 120766)] 120760:M 11 Jan 2025 17:43:13.094 * Loading RDB produced by version 6.2.17 120760:M 11 Jan 2025 17:43:13.094 * RDB age 9235 seconds 120760:M 11 Jan 2025 17:43:13.094 * RDB memory usage when created 0.85 Mb 120760:M 11 Jan 2025 17:43:13.094 # Done loading RDB, keys loaded: 0, keys expired: 0. 120760:M 11 Jan 2025 17:43:13.094 * DB loaded from disk: 0.000 seconds 120760:M 11 Jan 2025 17:43:13.094 * Ready to accept connections
1.3.2 查看程序运行状态
当程序运行到等待事件处理时,可以按
Ctrl+C组合键发送中断信号,使程序暂停运行。^C Thread 1 "redis-server" received signal SIGINT, Interrupt. 0x00007ffff7dc5fde in epoll_wait (epfd=5, events=0x55555577d600, maxevents=10128, timeout=100) at ../sysdeps/unix/sysv/linux/epoll_wait.c:30 30 ../sysdeps/unix/sysv/linux/epoll_wait.c: 没有那个文件或目录.输入
bt命令,查看程序当前的调用栈信息,了解程序在哪个函数、哪行代码处暂停。(gdb) bt #0 0x00007ffff7dc5fde in epoll_wait (epfd=5, events=0x55555577d600, maxevents=10128, timeout=100) at ../sysdeps/unix/sysv/linux/epoll_wait.c:30 #1 0x000055555559078e in aeApiPoll (tvp=<optimized out>, eventLoop=0x55555570c1e0) at /home/dogitry/code_study/redis/src/ae_epoll.c:113 #2 aeProcessEvents (eventLoop=eventLoop@entry=0x55555570c1e0, flags=flags@entry=27) at ae.c:395 #3 0x0000555555590acd in aeMain (eventLoop=0x55555570c1e0) at ae.c:487 #4 0x000055555558ca20 in main (argc=<optimized out>, argv=0x7fffffffdd58) at server.c:6474
1.3.3 查看线程信息
输入
info thread命令,查看当前程序的所有线程信息,包括线程 ID、目标 ID、当前执行的函数及行号等。(gdb) info thread Id Target Id Frame * 1 Thread 0x7ffff7c9d740 (LWP 120760) "redis-server" 0x00007ffff7dc5fde in epoll_wait (epfd=5, events=0x55555577d600, maxevents=10128, timeout=100) at ../sysdeps/unix/sysv/linux/epoll_wait.c:30 2 Thread 0x7ffff76b4640 (LWP 120764) "bio_close_file" __futex_abstimed_wait_common64 (private=0, cancel=true, abstime=0x0, op=393, expected=0, futex_word=0x5555556fbdc8 <bio_newjob_cond+40>) at ./nptl/futex-internal.c:57 3 Thread 0x7ffff6eb3640 (LWP 120765) "bio_aof_fsync" __futex_abstimed_wait_common64 (private=0, cancel=true, abstime=0x0, op=393, expected=0, futex_word=0x5555556fbdf8 <bio_newjob_cond+88>) at ./nptl/futex-internal.c:57 4 Thread 0x7ffff66b2640 (LWP 120766) "bio_lazy_free" __futex_abstimed_wait_common64 (private=0, cancel=true, abstime=0x0, op=393, expected=0, futex_word=0x5555556fbe28 <bio_newjob_cond+136>) --Type <RET> for more, q to quit, c to continue without paging--bt 57
1.3.4 查看和分析特定线程的调用栈
使用
thread命令加上线程编号,如thread 3,切换到指定的线程。(gdb) thread 3 [Switching to thread 3 (Thread 0x7ffff6eb3640 (LWP 11234))] #0 __futex_abstimed_wait_common64 (private=0, cancel=true, abstime=0x0, op=393, expected=0, futex_word=0x5555556fbdf8 <bio_newjob_cond+88>) at ./nptl/futex-internal.c:57 57 in ./nptl/futex-internal.c再次输入
bt命令,查看该线程的调用栈信息,以便进一步分析问题。(gdb) bt #0 __futex_abstimed_wait_common64 (private=0, cancel=true, abstime=0x0, op=393, expected=0, futex_word=0x5555556fbdf8 <bio_newjob_cond+88>) at ./nptl/futex-internal.c:57 #1 __futex_abstimed_wait_common (cancel=true, private=0, abstime=0x0, clockid=0, expected=0, futex_word=0x5555556fbdf8 <bio_newjob_cond+88>) at ./nptl/futex-internal.c:87 #2 __GI___futex_abstimed_wait_cancelable64 (futex_word=futex_word@entry=0x5555556fbdf8 <bio_newjob_cond+88>, expected=expected@entry=0, clockid=clockid@entry=0, abstime=abstime@entry=0x0, private=private@entry=0) at ./nptl/futex-internal.c:139 #3 0x00007ffff7d33ac1 in __pthread_cond_wait_common (abstime=0x0, clockid=0, mutex=0x5555556fbe68 <bio_mutex+40>, cond=0x5555556fbdd0 <bio_newjob_cond+48>) at ./nptl/pthread_cond_wait.c:503 #4 ___pthread_cond_wait (cond=cond@entry=0x5555556fbdd0 <bio_newjob_cond+48>, mutex=mutex@entry=0x5555556fbe68 <bio_mutex+40>) at ./nptl/pthread_cond_wait.c:627 #5 0x000055555560902a in bioProcessBackgroundJobs (arg=0x1) at bio.c:209 #6 0x00007ffff7d34b43 in start_thread (arg=<optimized out>) at ./nptl/pthread_create.c:442 --Type <RET> for more, q to quit, c to continue without paging-- #7 0x00007ffff7dc6a00 in clone3 () at ../sysdeps/unix/sysv/linux/x86_64/clone3.S:81
1.3.5 设置断点并继续运行程序
输入
br命令加上要设置断点的函数名,如br socket,在指定函数处设置断点。(gdb) br socket Breakpoint 1 at 0x7ffff7dc7ce0: file ../sysdeps/unix/syscall-template.S, line 120.输入
r命令,从头开始运行程序,程序会在设置的断点处暂停。(gdb) r The program being debugged has been started already. Start it from the beginning? (y or n) y Starting program: /home/dogitry/code_study/redis/src/redis-server [Thread debugging using libthread_db enabled] Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1". 164741:C 11 Jan 2025 19:03:05.384 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo 164741:C 11 Jan 2025 19:03:05.384 # Redis version=6.2.17, bits=64, commit=441001a4, modified=0, pid=164741, just started 164741:C 11 Jan 2025 19:03:05.384 # Warning: no config file specified, using the default config. In order to specify a config file use /home/dogitry/code_study/redis/src/redis-server /path/to/redis.conf 164741:M 11 Jan 2025 19:03:05.384 * monotonic clock: POSIX clock_gettime Breakpoint 1, socket () at ../sysdeps/unix/syscall-template.S:120 120 ../sysdeps/unix/syscall-template.S: 没有那个文件或目录.当程序暂停在断点处时,输入
bt命令查看调用栈信息,了解程序是如何到达该断点的。(gdb) bt #0 socket () at ../sysdeps/unix/syscall-template.S:120 #1 0x0000555555591db4 in _anetTcpServer (err=0x555555721e58 <server+760> "", port=6379, bindaddr=0x0, af=2, backlog=511) at anet.c:448 #2 0x0000555555591eec in anetTcpServer (err=0x555555721e58 <server+760> "", port=6379, bindaddr=0x5555556b107d "*", backlog=511) at anet.c:471 #3 0x00005555555996fc in listenToPort (port=6379, sfd=0x555555721d14 <server+436>) at server.c:3082 #4 0x0000555555599e04 in initServer () at server.c:3227 #5 0x00005555555a28db in main (argc=1, argv=0x7fffffffdd58) at server.c:6403使用
f命令加上帧编号,如f 1,查看特定帧的详细信息,包括函数参数、局部变量等。(gdb) f 1 #1 0x0000555555590e13 in _anetTcpServer (err=0x5555556e45d8 <server+760> "", port=<optimized out>, bindaddr=<optimized out>, af=af@entry=2, backlog=511) at anet.c:448 448 if ((s = socket(p->ai_family,p->ai_socktype,p->ai_protocol)) == -1)输入
n命令,执行下一行代码,继续观察程序的运行情况。(gdb) n socket () at ../sysdeps/unix/syscall-template.S:122 122 ../sysdeps/unix/syscall-template.S: 没有那个文件或目录.
1.3.6 查看变量值和局部变量信息
(gdb) br anetListen
Breakpoint 2 at 0x555555591aeb: file anet.c, line 401.
(gdb) c
Continuing.
Breakpoint 2, anetListen (err=0x555555721e58 <server+760> "", s=6, sa=0x55555572fe40, len=16, backlog=511, perm=0) at anet.c:401
401 if (bind(s,sa,len) == -1) {
(gdb) bt
#0 anetListen (err=0x555555721e58 <server+760> "", s=6, sa=0x55555572fe40, len=16, backlog=511, perm=0) at anet.c:401
#1 0x0000555555591e1d in _anetTcpServer (err=0x555555721e58 <server+760> "", port=6379, bindaddr=0x0, af=2, backlog=511) at anet.c:453
#2 0x0000555555591eec in anetTcpServer (err=0x555555721e58 <server+760> "", port=6379, bindaddr=0x5555556b107d "*", backlog=511) at anet.c:471
#3 0x00005555555996fc in listenToPort (port=6379, sfd=0x555555721d14 <server+436>) at server.c:3082
#4 0x0000555555599e04 in initServer () at server.c:3227
#5 0x00005555555a28db in main (argc=1, argv=0x7fffffffdd58) at server.c:6403
(gdb) f 1
#1 0x0000555555591e1d in _anetTcpServer (err=0x555555721e58 <server+760> "", port=6379, bindaddr=0x0, af=2, backlog=511) at anet.c:453
453 if (anetListen(err,s,p->ai_addr,p->ai_addrlen,backlog,0) == ANET_ERR) s = ANET_ERR;
在程序暂停时,输入
p命令加上变量名,如p port,查看指定变量的值。(gdb) p port $1 = 6379 (gdb) p port $1 = <optimized out> # 这里因为编译优化 被优化掉了输入
info locals命令,查看当前函数的局部变量信息,包括变量名、类型、值等。(gdb) info locals s = 6 rv = 0 _port = "6379\000" hints = {ai_flags = 1, ai_family = 2, ai_socktype = 1, ai_protocol = 0, ai_addrlen = 0, ai_addr = 0x0, ai_canonname = 0x0, ai_next = 0x0} servinfo = 0x55555572fe10 p = 0x55555572fe10
1.3.7 退出 GDB 调试器
输入
q命令,退出 GDB 调试器。如果提示有调试会话正在运行,是否要退出,输入y确认退出。(gdb) q A debugging session is active. Inferior 1 [process 120760] will be killed. Quit anyway? (y or n) y
2. Redis 底层数据结构
2.1 基础信息
2.1.1 如何进行调试
如果不熟悉源码,最好用的方式其实是“自底向上调试”。
先查资料,找到最底层调用的函数或方法
然后对这个方法打断点
程序运行,命中断点,查看调用栈
经过查阅小林Coding+AI,发现如下信息:
Redis 的核心数据结构(如字符串、哈希表、列表等)在源码中有对应的实现。可以通过在关键函数处设置断点来观察这些数据结构的使用。
以下是一些关键函数和数据结构:
字符串:
createStringObject(object.c)哈希表:
dictAdd(dict.c)列表:
listTypePush(t_list.c)集合:
setTypeAdd(t_set.c)有序集合:
zaddGenericCommand(t_zset.c)
我看了一下 object.c,发现真有一个 createStringObject 函数:

正好对应了小林 Coding 上所说的:

于是我在 GDB 处打上断点:
(gdb) br createRawStringObject
Breakpoint 1 at 0x5555555bb9c6: file object.c, line 78.
(gdb) c
Continuing.然后又开了一个终端运行 redis-cli ,存储一个字节数大于 44 的 string
127.0.0.1:6379> set name "123123123132132234234234242342dfefg43tsdf3rr2erwefwd"此时 GDB 处就可以触发断点了,
Thread 1 "redis-server" hit Breakpoint 1, createRawStringObject (ptr=0x5555557e4421 "123123123132132234234234242342dfefg43tsdf3rr2erwefwd\r\n", len=52) at object.c:78
78 return createObject(OBJ_STRING, sdsnewlen(ptr,len));
这样就可以用 bt 来看调用栈了,底部是直接从 main 开始的:
#0 createRawStringObject (ptr=0x5555557e4421 "123123123132132234234234242342dfefg43tsdf3rr2erwefwd\r\n", len=52) at object.c:78
#1 0x00005555555bbb81 in createStringObject (ptr=0x5555557e4421 "123123123132132234234234242342dfefg43tsdf3rr2erwefwd\r\n", len=52) at object.c:123
#2 0x00005555555b4261 in processMultibulkBuffer (c=0x5555557e0190) at networking.c:2038
#3 0x00005555555b469e in processInputBuffer (c=0x5555557e0190) at networking.c:2188
#4 0x00005555555b4b12 in readQueryFromClient (conn=0x5555557dbdd0) at networking.c:2292
#5 0x0000555555674e23 in callHandler (conn=0x5555557dbdd0, handler=0x5555555b47a1 <readQueryFromClient>)
at /home/dogitry/code_study/redis/src/connhelpers.h:79
#6 0x00005555556754eb in connSocketEventHandler (el=0x5555557361e0, fd=9, clientData=0x5555557dbdd0, mask=1) at connection.c:295
#7 0x00005555555908fd in aeProcessEvents (eventLoop=0x5555557361e0, flags=27) at ae.c:427
#8 0x0000555555590b39 in aeMain (eventLoop=0x5555557361e0) at ae.c:487
#9 0x00005555555a2b0d in main (argc=1, argv=0x7fffffffdd58) at server.c:6474如果我再针对 hash 类型获取其调用栈,如下:
#0 dictAdd (d=0x5555557c5560, key=0x5555557db321, val=0x5555557db380) at dict.c:302
#1 0x00005555555c098d in dbAdd (db=0x5555557c50d0, key=0x5555557f1370, val=0x5555557db380) at db.c:195
#2 0x00005555555ee597 in hashTypeLookupWriteOrCreate (c=0x5555557e0190, key=0x5555557f1370) at t_hash.c:459
#3 0x00005555555eeecb in hsetCommand (c=0x5555557e0190) at t_hash.c:668
#4 0x000055555559b3f2 in call (c=0x5555557e0190, flags=15) at server.c:3750
#5 0x000055555559cba8 in processCommand (c=0x5555557e0190) at server.c:4297
#6 0x00005555555b446a in processCommandAndResetClient (c=0x5555557e0190) at networking.c:2105
#7 0x00005555555b4725 in processInputBuffer (c=0x5555557e0190) at networking.c:2206
#8 0x00005555555b4b12 in readQueryFromClient (conn=0x5555557dbdd0) at networking.c:2292
#9 0x0000555555674e23 in callHandler (conn=0x5555557dbdd0, handler=0x5555555b47a1 <readQueryFromClient>)
at /home/dogitry/code_study/redis/src/connhelpers.h:79
#10 0x00005555556754eb in connSocketEventHandler (el=0x5555557361e0, fd=9, clientData=0x5555557dbdd0, mask=1) at connection.c:295
#11 0x00005555555908fd in aeProcessEvents (eventLoop=0x5555557361e0, flags=27) at ae.c:427
#12 0x0000555555590b39 in aeMain (eventLoop=0x5555557361e0) at ae.c:487
#13 0x00005555555a2b0d in main (argc=1, argv=0x7fffffffdd58) at server.c:6474我们会发现,不同类型的差异在 processInputBuffer 和 call 函数体现:
// String 类型 字符串
#2 0x00005555555b4261 in processMultibulkBuffer (c=0x5555557e0190) at networking.c:2038
#3 0x00005555555b469e in processInputBuffer (c=0x5555557e0190) at networking.c:2188
#4 0x00005555555b4b12 in readQueryFromClient (conn=0x5555557dbdd0) at networking.c:2292
// Hash 类型
#3 0x00005555555eeecb in hsetCommand (c=0x5555557e0190) at t_hash.c:668
#4 0x000055555559b3f2 in call (c=0x5555557e0190, flags=15) at server.c:3750
#5 0x000055555559cba8 in processCommand (c=0x5555557e0190) at server.c:4297
#6 0x00005555555b446a in processCommandAndResetClient (c=0x5555557e0190) at networking.c:2105
#7 0x00005555555b4725 in processInputBuffer (c=0x5555557e0190) at networking.c:2206
#8 0x00005555555b4b12 in readQueryFromClient (conn=0x5555557dbdd0) at networking.c:2292
// List 类型
#2 0x00005555555db599 in lpushCommand (c=0x5555557e0190) at t_list.c:264
#3 0x000055555559b3f2 in call (c=0x5555557e0190, flags=15) at server.c:3750
#4 0x000055555559cba8 in processCommand (c=0x5555557e0190) at server.c:4297
#5 0x00005555555b446a in processCommandAndResetClient (c=0x5555557e0190) at networking.c:2105
#6 0x00005555555b4725 in processInputBuffer (c=0x5555557e0190) at networking.c:2206
#7 0x00005555555b4b12 in readQueryFromClient (conn=0x5555557dbdd0) at networking.c:22922.1.2 键值对数据库是怎么实现的?

Redis 是使用了一个「哈希表」保存所有键值对,哈希表的最大好处就是让我们可以用 O(1) 的时间复杂度来快速查找到键值对。哈希表其实就是一个数组,数组中的元素叫做哈希桶。
Redis 的哈希桶是怎么保存键值对数据的呢?
哈希桶存放的是指向键值对数据的指针(dictEntry*),这样通过指针就能找到键值对数据,然后因为键值对的值可以保存字符串对象和集合数据类型的对象,所以键值对的数据结构中并不是直接保存值本身,而是保存了 void key 和 void value 指针,分别指向了实际的键对象和值对象,这样一来,即使值是集合数据,也可以通过 void * value 指针找到。
redisDb 结构,表示 Redis 数据库的结构,结构体里存放了指向了 dict 结构的指针;
dict 结构,结构体里存放了 2 个哈希表,正常情况下都是用「哈希表1」,「哈希表2」只有在 rehash 的时候才用,具体什么是 rehash,我在本文的哈希表数据结构会讲;
ditctht 结构,表示哈希表的结构,结构里存放了哈希表数组,数组中的每个元素都是指向一个哈希表节点结构(dictEntry)的指针;
dictEntry 结构,表示哈希表节点的结构,结构里存放了 **void key 和 void value 指针, key 指向的是 String 对象,而 value 则可以指向 String 对象,也可以指向集合类型的对象,比如 List 对象、Hash 对象、Set 对象和 Zset 对象。
特别说明下,void key 和 void value 指针指向的是 Redis 对象,Redis 中的每个对象都由 redisObject 结构表示,如下图:

对象结构里包含的成员变量:
type,标识该对象是什么类型的对象(String 对象、 List 对象、Hash 对象、Set 对象和 Zset 对象);
encoding,标识该对象使用了哪种底层的数据结构;
ptr,指向底层数据结构的指针。
以下为上述所提到数据结构的源码:
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error) */
} dict;
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;2.2 简单动态字符串 sds
用于替代 C 语言的字符串数组。
C 语言字符串数组有无法自动扩展、无法记录长度、无法记录包含 '\0' 的数据等缺点。
2.2.1 SDS 结构设计
typedef char *sds;
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */ // "Least Significant Bit" 表示最低的 3 位用于存储某种类型信息
char buf[];
};len 记录字符串长度。
这样获取字符串长度的时候,只需要返回这个成员变量值就行,时间复杂度只需要 O(1)。而 C 语言的 strlen 则需要遍历,时间复杂度 O(N) ,SDS 以空间换时间。
alloc 分配给字符数组的空间长度。
这样在修改字符串的时候,可以通过
alloc - len计算出剩余的空间大小,可以用来判断空间是否满足修改需求,如果不满足的话,就会自动扩展至执行修改所需的大小,然后才执行实际的修改操作,所以使用 SDS 既不需要手动修改 SDS 的空间大小,也不会出现缓冲区溢出的问题。
flags,用来表示不同类型的 SDS。
一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64 。
之所以 SDS 设计不同类型的结构体,是为了能灵活保存不同大小的字符串,从而有效节省内存空间。比如,在保存小字符串时,结构头占用空间也比较少。
buf[],字节数组,用来保存实际数据。
由于有个专门的 len 成员变量来记录长度,所以可存储包含 “\0” 的数据。因此不仅可以保存字符串,也可以保存二进制数据。
SDS 的 API 都是以处理二进制的方式来处理 SDS 存放在 buf[] 里的数据,程序不会对其中的数据做任何限制,数据写入的时候时什么样的,它被读取时就是什么样的。
但是 SDS 为了兼容部分 C 语言标准库的函数, SDS 字符串结尾还是会加上 “\0” 字符。
2.2.2 扩容规则
#define HI_SDS_MAX_PREALLOC (1024*1024) // 这里单位是字节 1MB
hisds hi_sdsMakeRoomFor(hisds s, size_t addlen) {
void *sh, *newsh;
size_t avail = hi_sdsavail(s);
size_t len, newlen;
char type, oldtype = s[-1] & HI_SDS_TYPE_MASK;
int hdrlen;
// s目前的剩余空间已足够,无需扩展,直接返回
/* Return ASAP if there is enough space left. */
if (avail >= addlen) return s;
// 获取目前s的长度
len = hi_sdslen(s);
sh = (char*)s-hi_sdsHdrSize(oldtype);
// 扩展之后 s 至少需要的长度
newlen = (len+addlen);
// 根据新长度,为s分配新空间所需要的大小
if (newlen < HI_SDS_MAX_PREALLOC)
// 新长度小于 1MB 则分配所需空间*2的空间
newlen *= 2;
else
// 否则,分配长度为目前长度+1MB
newlen += HI_SDS_MAX_PREALLOC;
// .... 其他代码
return s;
}扩容策略:
如果所需的SDS长度小于1 MB,扩容时会按照翻倍的方式进行,即新的长度为原来的2倍。
如果所需的SDS长度超过1 MB,扩容时会在新长度基础上增加1 MB。
内存管理:
在扩容之前,SDS API会先检查未使用空间是否足够。如果不够,API不仅会分配修改所需的空间,还会额外分配一些未使用空间。
这种机制的好处是,在下次操作SDS时,如果空间足够,API可以直接使用未使用空间,而不需要再次分配内存,从而减少内存分配次数。
2.2.3 取消字节对齐
注意这个 struct 上声明的 attribute ((__packed__)) ,其作用是:告诉编译器取消结构体在编译过程中的优化对齐,按照实际占用字节数进行对齐。
举个例子,假设下面这个结构体,它有两个成员变量,类型分别是 char 和 int,如下所示:
#include <stdio.h>
struct test1 {
char a;
int b;
}test1;
struct __attribute__((packed)) test2 {
char a;
int b;
}test2;
int main() {
printf("sizeof test1: %lu\n", sizeof(test1));
printf("sizeof test2: %lu\n", sizeof(test2));
return 0;
}输出:
sizeof test1: 8
sizeof test2: 5默认情况下,编译器是使用「字节对齐」的方式分配内存。虽然 char 类型只占一个字节,但是由于成员变量里有 int 类型,它占用了 4 个字节,所以在成员变量为 char 类型分配内存时,会分配 4 个字节,其中这多余的 3 个字节是为了字节对齐而分配的,相当于有 3 个字节被浪费掉了。
而紧凑方式的内存分配则会按照实际大小进行内存分配。

至于为什么默认要用字节对齐呢?因为以下几点:
大多数现代处理器从内存中读取数据时,是以固定大小的块(通常是 4 字节、8 字节或更大)为单位进行的。如果数据是对齐的,处理器可以一次性读取整个数据块。如果数据没有对齐,处理器可能需要多次访问内存才能读取完整的数据,这会显著降低性能。
内存对齐有助于提高缓存的使用效率。缓存行(Cache Line)通常是 64 字节或更大,对齐的数据可以更好地利用缓存行,减少缓存未命中(Cache Miss)的情况。
等等……
假设缓存行大小为 64 字节,且有一个 8 字节的数据对象(例如一个 double 类型的数据)。
情况 1:数据对齐:
数据对象的起始地址是 64 字节的倍数(例如地址
0x1000)。这个数据对象完全存储在一个缓存行中(例如缓存行
0x1000到0x103F)。CPU 只需要加载一个缓存行即可访问该数据对象。
情况 2:数据未对齐:
数据对象的起始地址不是 64 字节的倍数(例如地址
0x1004)。这个数据对象可能跨越两个缓存行(例如缓存行
0x1000到0x103F和0x1040到0x107F)。CPU 需要加载两个缓存行才能访问该数据对象,增加了缓存未命中的概率。
SDS 在设计上牺牲了以上特性,因此 Redis 的 SDS 适合存储小字符串。例如使用 embstr 编码,将短字符串直接嵌入到对象结构中,避免额外的内存分配。
2.3 压缩列表 ziplist
用于替代普通双向链表。
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value; // 节点值也是指针
}
typedef struct list {
// 链表头节点
listNode *head;
// 链表尾节点
listNode *tail;
// 节点值复制函数
void *(*dup)(void *ptr);
// 节点值释放函数
void (*free)(void *ptr);
// 节点值比较函数
int (*match)(void *ptr, void *key);
// 链表节点数量 获取链表中的节点数量的时间复杂度只需O(1)
unsigned long len;
} list;双向链表优点:
获得前置后置节点、表头表尾节点、链表长度的时间复杂度都是 O(1)
listNode 链表节使用 void* 指针保存节点值,并且可以通过 list 结构的 dup、free、match 函数指针为节点设置该节点类型特定的函数,因此链表节点可以保存各种不同类型的值;
要解决双向链表的问题:
链表每个节点之间的内存都是不连续的,意味着无法很好利用 CPU 缓存。
保存一个链表节点的值都需要一个链表节点结构头的分配,内存开销较大。
2.3.1 ziplist 结构设计
压缩列表是 Redis 为了节约内存而开发的,它是由连续内存块组成的顺序型数据结构,有点类似于数组。

zlbytes:32 位无符号整数,表示整个 ziplist 占用的字节数。zltail:32 位无符号整数,表示最后一个 entry 的偏移量,即距离起始地址由多少字节。zllen:16 位无符号整数,表示 entry 的数量。entry:ziplist 中的每个元素。zlend:8 位无符号整数,固定为255=0xFF,表示 ziplist 的结束。

压缩列表节点(entry)的构成如下:
prevlen,记录了「前一个节点」的长度,目的是为了实现从后向前遍历;
encoding,记录了当前节点实际数据的「类型和长度」,类型主要有两种:字符串和整数。
data,记录了当前节点的实际数据,类型和长度都由
encoding决定;
注意:以上描述在源代码文件的注释中都有详细解释,但是都没有在源码显式地定义为独立的结构体与变量,都是通过紧凑的二进制编码直接存储在内存中。这些字段的定义和解析是通过位操作和编码规则来实现的,代码中通过宏定义与 zlentry 结构体对其进行了封装操作。

/* Return total bytes a ziplist is composed of. */
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
/* Return the offset of the last item inside the ziplist. */
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
/* Return the length of a ziplist, or UINT16_MAX if the length cannot be
* determined without scanning the whole ziplist. */
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
/* We use this function to receive information about a ziplist entry.
* Note that this is not how the data is actually encoded, is just what we
* get filled by a function in order to operate more easily. */
typedef struct zlentry {
unsigned int prevrawlensize; /* Bytes used to encode the previous entry len*/
unsigned int prevrawlen; /* Previous entry len. */
unsigned int lensize; /* Bytes used to encode this entry type/len.
For example strings have a 1, 2 or 5 bytes
header. Integers always use a single byte.*/
unsigned int len; /* Bytes used to represent the actual entry.
For strings this is just the string length
while for integers it is 1, 2, 3, 4, 8 or
0 (for 4 bit immediate) depending on the
number range. */
unsigned int headersize; /* prevrawlensize + lensize. */
unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on
the entry encoding. However for 4 bits
immediate integers this can assume a range
of values and must be range-checked. */
unsigned char *p; /* Pointer to the very start of the entry, that
is, this points to prev-entry-len field. */
} zlentry;2.3.2 节点空间大小动态分配
压缩列表节点包含三部分内容:
prevlen,记录了「前一个节点」的长度,目的是为了实现从后向前遍历;
encoding,记录了当前节点实际数据的「类型和长度」,类型主要有两种:字符串和整数。
data,记录了当前节点的实际数据,类型和长度都由
encoding决定;也称作 content
当我们往压缩列表中插入数据时,压缩列表就会根据数据类型是字符串还是整数,以及数据的大小,会使用不同空间大小的 prevlen 和 encoding 这两个元素里保存的信息,这种根据数据大小和类型进行不同的空间大小分配的设计思想,正是 Redis 为了节省内存而采用的。
prevlen 属性:空间大小与其值有关
如果前一个节点的长度小于 254 字节,那么 prevlen 属性需要用 1 字节的空间来保存这个长度值;
如果前一个节点的长度大于等于 254 字节,那么 prevlen 属性需要用 5 字节的空间来保存这个长度值;
encoding 属性:空间大小跟数据是字符串还是整数,以及字符串的长度有关

如果当前节点的数据是整数,则 encoding 会使用 1 字节的空间进行编码,也就是 encoding 长度为 1 字节。通过 encoding 确认了整数类型,就可以确认整数数据的实际大小了,比如如果 encoding 编码确认了数据是 int16 整数,那么 data 的长度就是 int16 的大小。(4位 1~12,8位,16位,32位,64位)
如果当前节点的数据是字符串,根据字符串的长度大小,encoding 会使用 1 字节/2字节/5字节的空间进行编码,encoding 编码的前两个 bit 表示数据的类型,后续的其他 bit 标识字符串数据的实际长度,即 data 的长度。
但是如此可能会引发一个问题:
压缩列表新增某个元素或修改某个元素时,如果空间不不够,压缩列表占用的内存空间就需要重新分配。而当新插入的元素较大时,可能会导致后续元素的 prevlen 占用空间都发生变化,从而引起「连锁更新」问题,导致每个元素的空间都要重新分配,造成访问压缩列表性能的下降。
现在假设一个压缩列表中有多个连续的、长度在 250~253 之间的节点,如下图:

因为这些节点长度值小于 254 字节,所以 prevlen 属性需要用 1 字节的空间来保存这个长度值。
这时,如果将一个长度大于等于 254 字节的新节点加入到压缩列表的表头节点,即新节点将成为 e1 的前置节点,如下图:
注:时间复杂度是O(n)

因为 e1 节点的 prevlen 属性只有 1 个字节大小,无法保存新节点的长度,此时就需要对压缩列表的空间重分配操作,并将 e1 节点的 prevlen 属性从原来的 1 字节大小扩展为 5 字节大小。
多米诺牌的效应就此开始。
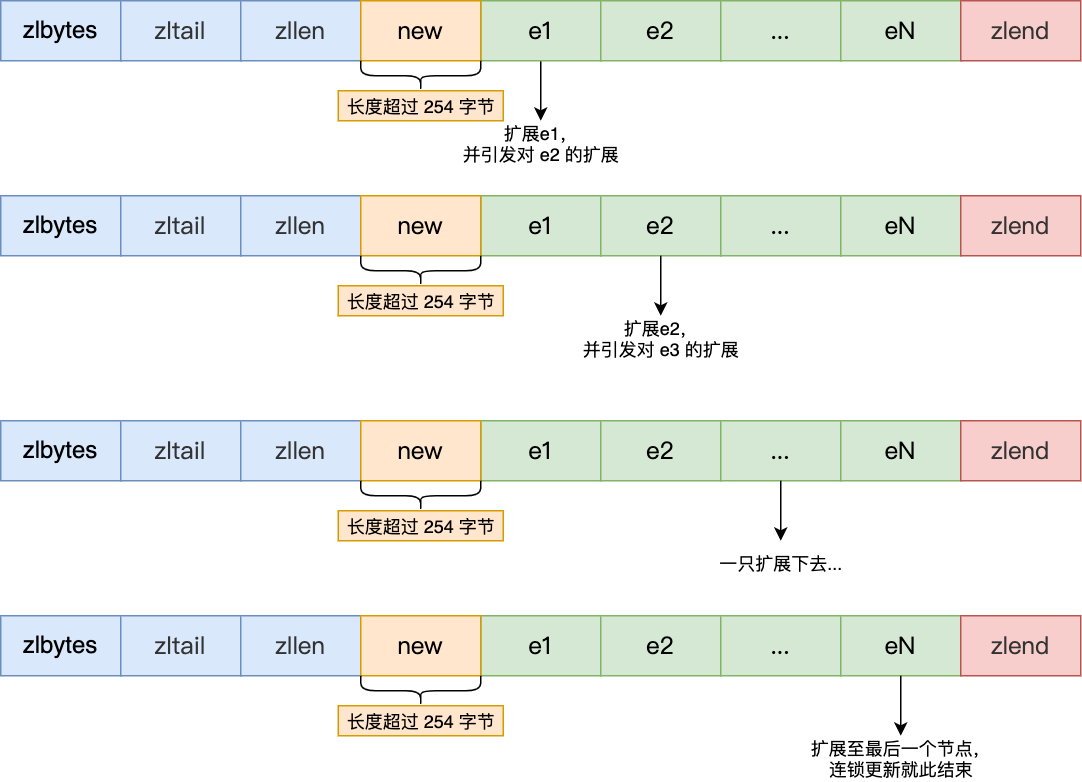
e1 原本的长度在 250~253 之间,因为刚才的扩展空间,此时 e1 的长度就大于等于 254 了,因此原本 e2 保存 e1 的 prevlen 属性也必须从 1 字节扩展至 5 字节大小。
正如扩展 e1 引发了对 e2 扩展一样,扩展 e2 也会引发对 e3 的扩展,而扩展 e3 又会引发对 e4 的扩展.... 一直持续到结尾。
因此压缩列表适合存储少量的数据,如果大量数据都要重新扩展,会造成 Redis 进程阻塞。
2.4 哈希表 dictht
这玩意儿可太重要了,Redis本身就是 Key-Value 数据库,而哈希表是 Redis 实现 Key-Value 存储的核心数据结构。
用于改进普通哈希表。
有些地方和 Java 8 之前数组+链表的方式很像,很多相似的思想就不重复了。
2.4.1 哈希表结构设计
typedef struct dictht {
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值
unsigned long sizemask;
//该哈希表已有的节点数量
unsigned long used;
} dictht;
typedef struct dictEntry {
//键值对中的键
void *key;
//键值对中的值
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
//指向下一个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
dictEntry 结构里键值对中的值是一个「联合体 v」定义的,因此,键值对中的值可以是一个指向实际值的指针,或者是一个无符号的 64 位整数或有符号的 64 位整数或double 类的值。这么做的好处是可以节省内存空间,因为当「值」是整数或浮点数时,就可以将值的数据内嵌在 dictEntry 结构里,无需再用一个指针指向实际的值,从而节省了内存空间。
2.4.2 渐进式 rehash
Redis 的 dict 结构体定义了两个哈希表:
typedef struct dict {
…
//两个Hash表,交替使用,用于rehash操作
dictht ht[2];
…
} dict;之所以定义了 2 个哈希表,是因为进行 rehash 的时候,需要用上 2 个哈希表了。

如果按照 Java 那种方式,在 rehash 的时候,先开一个 2倍大小的哈希表作为“哈希表2”,然后将遍历哈希表1将每个元素进行数据迁移;迁移完成后,「哈希表 1 」的空间会被释放,并把「哈希表 2」 设置为「哈希表 1」,然后在「哈希表 2」 新创建一个空白的哈希表,为下次 rehash 做准备。

但是有个问题:在数据量大+高并发环境下,迁移过程涉及到大量的数据拷贝。Java 是支持多线程的,但是对于单线程的 Redis 可能就会阻塞,无法服务其他请求了。
于是针对 Redis 推出了渐进式 rehash:
给「哈希表 2」 分配空间;
在 rehash 进行期间,每次哈希表元素进行新增、删除、查找或者更新操作时,Redis 除了会执行对应的操作之外,还会顺序将「哈希表 1 」中索引位置上的所有 key-value 迁移到「哈希表 2」 上;
随着处理客户端发起的哈希表操作请求数量越多,最终在某个时间点会把「哈希表 1 」的所有 key-value 迁移到「哈希表 2」,从而完成 rehash 操作。
这样就巧妙地把一次性大量数据迁移工作的开销,分摊到了多次处理请求的过程中,避免了一次性 rehash 的耗时操作。
在进行渐进式 rehash 的过程中,会有两个哈希表,所以在渐进式 rehash 进行期间,哈希表元素的删除、查找、更新等操作都会在这两个哈希表进行。比如,查找一个 key 的值的话,先会在「哈希表 1」 里面进行查找,如果没找到,就会继续到哈希表 2 里面进行找到。
另外,在渐进式 rehash 进行期间,新增一个 key-value 时,会被保存到「哈希表 2 」里面,而「哈希表 1」 则不再进行任何添加操作,这样保证了「哈希表 1 」的 key-value 数量只会减少,随着 rehash 操作的完成,最终「哈希表 1 」就会变成空表。
和 Java-HashMap 类似,Redis-dictht 也有负载因子 LoadFactor:
当负载因子大于等于 1 ,并且 Redis 没有在执行 bgsave 命令或者 bgrewiteaof 命令,也就是没有执行 RDB 快照或没有进行 AOF 重写的时候,就会进行 rehash 操作。
当负载因子大于等于 5 时,此时说明哈希冲突非常严重了,不管有没有有在执行 RDB 快照或 AOF 重写,都会强制进行 rehash 操作
2.5 跳表 zskiplist
这数据结构有点意思,可以和 B+ 树掰掰手腕。
用于有序数据的存储。
2.5.1 跳表结构设计
链表在查找元素的时候,因为需要逐一查找,所以查询效率非常低,时间复杂度是O(N),于是就出现了跳表。跳表是在链表基础上改进过来的,实现了一种「多层」的有序链表,这样的好处是能快读定位数据。
如下,如果我们要在链表中查找节点 4 这个元素,只能从头开始遍历链表,需要查找 4 次,而使用了跳表后,只需要查找 2 次就能定位到节点 4,因为可以在头节点直接从 L2 层级跳到节点 3,然后再往前遍历找到节点 4。

每个跳表节点的数据结构设计如下:
typedef struct zskiplistNode {
// Zset 对象的元素值
sds ele;
// 元素权重值
double score;
// 后向指针
struct zskiplistNode *backward;
// 节点的level数组,保存每层上的前向指针和跨度
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;元素值 ele :sds 类型,用于存储 Node 元素
权重值 score:double 类型,用于被查找,权重越大越靠后
后向指针 backward:由双向链表保留而来的,指向上一个元素(第 0 层)
层级数组 level[]:是 zskiplistLevel 类型的集合,下标代表层级,level[0] 即代表第 0 层。每一层的元素都有:
前向指针 forward:由双向链表保留而来,指向该层的下一个元素
跨度 span:该层下一个元素距离本元素的距离,用于计算节点在跳表中的排位。
上述图中的跳表是这样构建的(这是Java代码,大致意思相通,仅供理解)
public class Main {
public static void main(String[] args) {
// 构建所有元素
ZSkipListNode header = new ZSkipListNode(null, 0.0,new ZSkipListLevel[3]);
ZSkipListNode node1 = new ZSkipListNode("a", 1.0, new ZSkipListLevel[3]);
ZSkipListNode node2 = new ZSkipListNode("ab", 2.0, new ZSkipListLevel[3]);
ZSkipListNode node3 = new ZSkipListNode("abc", 3.0, new ZSkipListLevel[3]);
ZSkipListNode node4 = new ZSkipListNode("abcd", 4.0, new ZSkipListLevel[3]);
ZSkipListNode node5 = new ZSkipListNode("abcde", 4.0, new ZSkipListLevel[3]);
// 构建层级 0
header.levels[0].forward = node1; header.levels[0].span = 1;
node1.levels[0].forward = node2; node1.levels[0].span = 1; node1.backward = header;
node2.levels[0].forward = node3; node2.levels[0].span = 1; node2.backward = node1;
node3.levels[0].forward = node4; node3.levels[0].span = 1; node3.backward = node2;
node4.levels[0].forward = node5; node4.levels[0].span = 1; node4.backward = node3;
node5.levels[0].forward = null; node5.levels[0].span = 0; node5.backward = node4;
// 构建层级 1
header.levels[1].forward = node2; header.levels[1].span = 2;
node2.levels[1].forward = node3; node2.levels[1].span = 1;
node3.levels[1].forward = node5; node3.levels[1].span = 5;
node5.levels[1].span = 0;
// 构建层级 2
header.levels[2].forward = node3; header.levels[2].span = 3;
node3.levels[2].span = 0;
}
}
class ZSkipListNode {
String ele;
double score;
ZSkipListNode backward;
ZSkipListLevel[] levels;
public ZSkipListNode(String ele, double score, ZSkipListLevel[] levels) {
this.ele = ele;
this.score = score;
this.levels = levels;
}
}
class ZSkipListLevel {
ZSkipListNode forward;
long span;
}头节点其实也是 zskiplistNode 跳表节点,只不过头节点的后向指针、权重、元素值都没有用到,所以图中省略了这部分。
最后我们再用一个数据结构代表最上层的“跳表”结构体,里面的元素我们都可以用 O(1) 复杂度获取:
typedef struct zskiplist {
struct zskiplistNode *header, *tail; // 头尾节点指针
unsigned long length; // 长度
int level; // 目前的跳表最大层数
} zskiplist;2.5.2 跳表节点查询
查找一个跳表节点的过程时,跳表会从头节点的最高层开始,逐一遍历每一层。在遍历某一层的跳表节点时,会用跳表节点中的 SDS 类型的元素和元素的权重来进行判断,共有两个判断条件:
如果当前节点的权重「小于」要查找的权重时,跳表就会访问该层上的下一个节点。
如果当前节点的权重「等于」要查找的权重时,并且当前节点的 SDS 类型数据「小于」要查找的数据时,跳表就会访问该层上的下一个节点。
如果上面两个条件都不满足,或者下一个节点为空时,跳表就会使用目前遍历到的节点的 level 数组里的下一层指针,然后沿着下一层指针继续查找,这就相当于跳到了下一层接着查找。
举个例子,下图有个 3 层级的跳表。
如果要查找「元素:abcd,权重:4」的节点,查找的过程是这样的:
先从头节点的最高层开始,L2 指向了「元素:abc,权重:3」节点,这个节点的权重比要查找节点的小,所以要访问该层上的下一个节点;
但是该层的下一个节点是空节点( leve[2]指向的是空节点),于是就会跳到「元素:abc,权重:3」节点的下一层去找,也就是 level[1];
「元素:abc,权重:3」节点的 leve[1] 的下一个指针指向了「元素:abcde,权重:4」的节点,然后将其和要查找的节点比较。虽然「元素:abcde,权重:4」的节点的权重和要查找的权重相同,但是当前节点的 SDS 类型数据「大于」要查找的数据,所以会继续跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve[0];
「元素:abc,权重:3」节点的 leve[0] 的下一个指针指向了「元素:abcd,权重:4」的节点,该节点正是要查找的节点,查询结束。
2.5.3 跳表层数设置
为了降低查询复杂度,我们就需要维持相邻层结点数间的关系。
跳表的相邻两层的节点数量最理想的比例是 2:1,查找复杂度可以降低到 O(logN)。
下图的跳表就是,相邻两层的节点数量的比例是 2 : 1。

但是怎么维持呢?如果像二叉平衡树那样,新增节点或者删除节点时,来调整跳表节点以维持比例的方法的话,会带来额外的开销。
Redis 则采用一种巧妙的方法是,跳表在创建节点的时候,随机生成每个节点的层数,并没有严格维持相邻两层的节点数量比例为 2 : 1 的情况。
具体的做法是,跳表在创建节点时候,会生成范围为[0-1]的一个随机数,如果这个随机数小于 0.25(相当于概率 25%),那么层数就增加 1 层,然后继续生成下一个随机数,直到随机数的结果大于 0.25 结束,最终确定该节点的层数。

这样的做法,相当于每增加一层的概率不超过 25%,层数越高,概率越低,层高最大限制是 64。
虽然我前面讲解跳表的时候,图中的跳表的「头节点」都是 3 层高,但是其实如果层高最大限制是 64,那么在创建跳表「头节点」的时候,就会直接创建 64 层高的头节点。
如下代码,创建跳表时,头节点的 level 数组有 ZSKIPLIST_MAXLEVEL个元素(层),节点不存储任何 member 和 score 值,level 数组元素的 forward 都指向NULL, span值都为0。
/* Create a new skiplist. */
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl));
zsl->level = 1;
zsl->length = 0;
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
zsl->tail = NULL;
return zsl;
}2.5.4 跳表 VS B+树 VS 红黑树
为什么 Redis 用跳表不用红黑树?
编码:跳表更容易实现、调试。
占用:跳表的指针内存占用不比平衡树占用多。
缓存:跳表的缓存局部性由于经常有范围查找,不会比平衡树差。
其他解释:Redis 是内存数据库,不存在 I/O,层高不是跳表的劣势(为什么不用 B+ 树),也少了旋转平衡的开销(红黑树)。
有人问:Skip lists consume more memory in pointers and are generally slower than btrees because of poor memory locality so traversing them means lots of cache misses.

为什么 MySQL InnoDB & MyIsam 用 B+ 树,不用跳表?
B+树是多叉树结构,每个结点都是一个16k的数据页,能存放较多索引信息,所以扇出很高。三层左右就可以存储2kw左右的数据。也就是说查询一次数据,如果这些数据页都在磁盘里,那么最多需要查询 3 次磁盘IO。
跳表是链表结构,一条数据一个结点,如果最底层要存放2kw数据,且每次查询都要能达到二分查找的效果,2kw大概在2的24次方左右,所以,跳表大概高度在24层左右。最坏情况下,这24层数据会分散在不同的数据页里,也即是查一次数据最多会经历 24 次磁盘IO。
因此存放同样量级的数据,B+树的高度比跳表的要少,如果放在mysql数据库上来说,就是磁盘IO次数更少,因此B+树查询更快。
而针对写操作,B+树需要拆分合并索引数据页,跳表则独立插入,并根据随机函数确定层数,没有旋转和维持平衡的开销,因此跳表的写入性能会比B+树要好。
结论:B+树相比跳表,读性能好、写性能差。B+ 树更适合读多写少的场景。
2.6 实现:Redis 数据类型
以下,右侧的“+”号,都是元素类型较小/元素数量少而优化的结构,如压缩链表等。
2.6.1 String 内部实现 + long
String 类型的底层的数据结构实现主要是 int 和 SDS(简单动态字符串)。
字符串对象的内部编码(encoding)有 3 种 :int、raw和 embstr。

如果一个字符串对象保存的是整数值,并且这个整数值可以用long类型来表示,那么字符串对象会将整数值保存在字符串对象结构的ptr属性里面(将void*转换成 long),并将字符串对象的编码设置为int。

如果字符串对象保存的是一个短字符串,长度小于等于 44 字节,那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串,并将对象的编码设置为embstr, embstr编码是专门用于保存短字符串的一种优化编码方式:

如果字符串对象保存的是一个长字符串,长度大于 44 字节,那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串,并将对象的编码设置为raw:

可以看到embstr和raw编码都会使用SDS来保存值,但不同之处在于embstr会通过一次内存分配函数来分配一块连续的内存空间来保存redisObject和SDS,而raw编码会通过调用两次内存分配函数来分别分配两块空间来保存redisObject和SDS。Redis这样做会有很多好处:
embstr编码将创建字符串对象所需的内存分配次数从raw编码的两次降低为一次;释放
embstr编码的字符串对象同样只需要调用一次内存释放函数;因为
embstr编码的字符串对象的所有数据都保存在一块连续的内存里面可以更好的利用 CPU 缓存提升性能。
缺点:
如果字符串的长度增加需要重新分配内存时,整个redisObject和sds都需要重新分配空间,所以embstr编码的字符串对象实际上是不可变的,redis没有为embstr编码的字符串对象编写任何相应的修改程序。当我们对embstr编码的字符串对象执行任何修改命令(例如append)时,程序会先将对象的编码从embstr转换成raw,然后再执行修改命令。
2.6.2 List 内部实现 + quicklist
3.2 版本之前,List 类型的底层数据结构是由双向链表或压缩列表实现的:
如果列表的元素个数小于
512个,列表每个元素的值都小于64字节,用压缩链表;否则,用双向链表。
3.2 版本后,List 类型的数据结构只由 quicklist 实现。

在向 quicklist 添加一个元素的时候,不会像普通的链表那样,直接新建一个链表节点。而是会检查插入位置的压缩列表是否能容纳该元素,如果能容纳就直接保存到 quicklistNode 结构里的压缩列表,如果不能容纳,才会新建一个新的 quicklistNode 结构。
quicklist 会控制 quicklistNode 结构里的压缩列表的大小或者元素个数,来规避潜在的连锁更新的风险,但是这并没有完全解决连锁更新的问题。
2.6.3 Hash 内部实现 + listpack
Hash 类型的底层数据结构是由压缩列表或哈希表实现的:
如果哈希类型元素个数小于
512个,所有值小于64字节,用压缩列表作为 Hash 类型的底层数据结构;否则用哈希表。
7.0 版本之后,压缩列表被废弃,使用 listpack 数据结构。
上图 listpack,下图 ziplist。


可以看到,listpack 没有压缩列表中记录 prevlen 的字段了,改成了 len 只记录当前节点的长度,当我们向 listpack 加入一个新元素的时候,不会影响其他节点的长度字段的变化,从而避免了压缩列表的连锁更新问题。
对于 prevlen 的作用,listpack 改成 len 之后,可以通过下面的函数算出 backlen,一样可以支持从后往前遍历。
/* 解码 backlen 并返回其值。如果编码无效(使用超过 5 个字节),
* 返回 UINT64_MAX 以报告问题。*/
uint64_t lpDecodeBacklen(unsigned char *p) {
uint64_t val = 0; // 用于存储解码后的值
uint64_t shift = 0; // 位移量,初始为 0
do {
// 获取当前字节的低 7 位并将其添加到 val 中,p[0] & 127 保留低 7 位
val |= (uint64_t)(p[0] & 127) << shift;
// 如果当前字节的高位不是 1,表示解码结束,跳出循环
if (!(p[0] & 128)) break;
// 如果高位是 1,继续解码,位移量增加 7
shift += 7;
// 向前移动指针,准备读取下一个字节
p--;
// 如果位移量超过 28,表示编码无效,返回 UINT64_MAX
if (shift > 28) return UINT64_MAX;
} while(1); // 循环直到解码完成
return val; // 返回解码后的值
}2.6.4 Set 内部实现 + 整数集合
Set 类型的底层数据结构是由哈希表或整数集合实现的:
如果集合中的元素都是整数且元素个数小于
512个,Redis 会使用整数集合作为 Set 类型的底层数据结构;否则使用哈希表作为 Set 类型的底层数据结构。
整数集合数据结构:
typedef struct intset {
uint32_t encoding; // 编码方式
uint32_t length; // 元素数量
int8_t contents[]; // 元素数组
} intset;虽然 contents 被声明为 int8_t 类型的数组,但是实际上 contents 数组并不保存任何 int8_t 类型的元素,contents 数组的真正类型取决于 intset 结构体里的 encoding 属性的值。
比如,如果 encoding 属性值为 INTSET_ENC_INT16,那么 contents 就是一个 int16_t 类型的数组,数组中每一个元素的类型都是 int16_t;
不同类型的 contents 数组,意味着数组的大小也会不同。
整数集合会有一个升级规则,就是当我们将一个新元素加入到整数集合里面,如果新元素的类型(int32_t)比整数集合现有所有元素的类型(int16_t)都要长时,整数集合需要先进行升级,也就是按新元素的类型(int32_t)扩展 contents 数组的空间大小,然后才能将新元素加入到整数集合里。这样,就可以一开始不存大元素,可以先存小元素,遇到大元素再扩容,整数集合升级的好处是节省内存资源。
整个过程分两步:
扩容数组:以便存下新类型的元素

转换类型:从后向前重新分配位置

整数集合不支持降级操作。
2.6.5 ZSet 内部实现 + listpack
Zset 类型的底层数据结构是由压缩列表或跳表实现的:
如果有序集合的元素个数小于
128个,并且每个元素的值小于64字节时,Redis 会使用压缩列表作为 Zset 类型的底层数据结构;否则会使用跳表作为数据结构。
在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了。
3. Redis 线程模型

4. Redis 删除
4.1 过期删除策略
4.1.1 如何判定 key 过期?
每当我们对一个 key 设置了过期时间时,Redis 会把该 key 带上过期时间存储到一个过期字典(expires dict)中,也就是说「过期字典」保存了数据库中所有 key 的过期时间。
过期字典存储在 redisDb 结构中,如下:
typedef struct redisDb {
dict *dict; /* 数据库键空间,存放着所有的键值对 */
dict *expires; /* 键的过期时间 */
....
} redisDb;过期字典数据结构结构如下:
过期字典的 key 是一个指针,指向某个键对象;
过期字典的 value 是一个 long long 类型的整数,这个整数保存了 key 的过期时间;
过期字典的数据结构如下图所示:

字典实际上是哈希表,哈希表的最大好处就是让我们可以用 O(1) 的时间复杂度来快速查找。当我们查询一个 key 时,Redis 首先检查该 key 是否存在于过期字典中:
如果不在,则正常读取键值;
如果存在,则会获取该 key 的过期时间,然后与当前系统时间进行比对,如果比系统时间大,那就没有过期,否则判定该 key 已过期。
4.2.2 三种删除策略
定时删除
策略:在设置 key 的过期时间时,同时创建一个定时事件,当时间到达时,由事件处理器自动执行 key 的删除操作。
优点:保证尽快删除 key,对内存友好
缺点:不断轮询,大量 key 可能同时过期,对 CPU 不友好
惰性删除
策略:不主动删除过期键,每次从数据库访问 key 时,都检测 key 是否过期,如果过期则删除该 key。
优点:每次访问才检查 key,对 CPU 友好
缺点:已过期但没被访问的 key,对内存不友好
定期删除
策略:每隔一段时间「随机」从数据库中取出一定数量的 key 进行检查,并删除其中的过期key。
优点:通过限制删除操作执行的时长和频率,来减少删除操作对 CPU 的影响,同时也能删除一部分过期的数据减少了过期键对空间的无效占用。
缺点:
内存清理方面没有定时删除效果好,同时没有惰性删除使用的系统资源少。
难以确定删除操作执行的时长和频率。如果执行的太频繁,定期删除策略变得和定时删除策略一样,对CPU不友好;如果执行的太少,那又和惰性删除一样了,过期 key 占用的内存不会及时得到释放。
Redis 选择「惰性删除+定期删除」这两种策略配和使用,以求在合理使用 CPU 时间和避免内存浪费之间取得平衡。
4.2.3 Redis 的删除策略
惰性删除策略源码:
在访问或者修改 key 之前,都会调用 expireIfNeeded 函数对其进行检查,检查 key 是否过期
如果过期,则删除该 key(同步 or 异步由配置决定),然后返回 null 给客户端
反之不做任何处理,然后返回正常的键值对给客户端
/ * 该函数的返回值为 0,表示键仍然有效;如果键已过期,则返回 1。 */
int expireIfNeeded(redisDb *db, robj *key) {
// 如果键未过期,直接返回 0,表示键有效
if (!keyIsExpired(db,key)) return 0;
/* 如果当前在从节点的上下文中,我们不会逐出已过期的键,而是立即返回:
* 从节点的键过期是由主节点控制的,主节点会为过期的键发送合成的 DEL 操作。 */
if (server.masterhost != NULL) return 1;
/* 如果客户端被暂停,我们保持当前数据集不变,
* 但返回给客户端我们认为正确的状态。通常,在暂停结束时,我们会正确地过期键,或者我们会发生故障转移,新的主节点会发送过期操作。 */
if (checkClientPauseTimeoutAndReturnIfPaused()) return 1;
/* 删除已过期的键 */
deleteExpiredKeyAndPropagate(db,key);
return 1;
}
void deleteExpiredKeyAndPropagate(redisDb *db, robj *keyobj) {
// ...
// 如果 server.lazyfree_lazy_expire 为 1 表示异步删除,反之同步删除;
if (server.lazyfree_lazy_expire)
dbAsyncDelete(db,keyobj);
else
dbSyncDelete(db,keyobj);
// ...
}定期删除策略伪代码:
从过期字典中随机抽取 20 个 key;
检查这 20 个 key 是否过期,并删除已过期的 key;
如果本轮检查的已过期 key 的数量,超过 5 个(20/4),也就是「已过期 key 的数量」占比「随机抽取 key 的数量」大于 25%,则继续重复步骤 1;如果已过期的 key 比例小于 25%,则停止继续删除过期 key,然后等待下一轮再检查。
定期删除循环流程的时间有上限,默认不会超过 25ms。
do {
//已过期的数量
expired = 0;
//随机抽取的数量
num = 20;
while (num--) {
//1. 从过期字典中随机抽取 1 个 key
//2. 判断该 key 是否过期,如果已过期则进行删除,同时对 expired++
}
// 超过时间限制则退出
if (timelimit_exit) return;
/* 如果本轮检查的已过期 key 的数量,超过 25%,则继续随机抽查,否则退出本轮检查 */
} while (expired > 20/4); 4.2 内存淘汰策略
4.2.1 Redis 八种内存淘汰策略
noeviction
默认策略。
当内存不足时,新写入操作会返回错误,不会删除任何键。
适用于确保数据不丢失的场景。
allkeys-lru
从所有键中,移除 最近最少使用 (LRU) 的键。
适用于需要淘汰长时间未使用的键的场景。
volatile-lru
从设置了过期时间的键中,移除 最近最少使用 (LRU) 的键。
适用于只淘汰过期键的场景。
allkeys-random
从所有键中,随机移除一个键。
适用于不需要特定淘汰规则的场景。
volatile-random
从设置了过期时间的键中,随机移除一个键。
适用于只淘汰过期键且不需要特定规则的场景。
volatile-ttl
从设置了过期时间的键中,移除 剩余生存时间 (TTL) 最短的键。
适用于优先淘汰即将过期的键的场景。
allkeys-lfu
从所有键中,移除 最不经常使用 (LFU) 的键。
适用于需要淘汰使用频率最低的键的场景。
volatile-lfu
从设置了过期时间的键中,移除 最不经常使用 (LFU) 的键。
适用于只淘汰过期键且需要根据使用频率淘汰的场景。
4.2.2 Redis LRU
LRU 全称是 Least Recently Used 翻译为最近最少使用,会选择淘汰最近最少使用的数据。
传统 LRU 算法的实现是基于「链表」结构,链表中的元素按照操作顺序从前往后排列,最新操作的键会被移动到表头,当需要内存淘汰时,只需要删除链表尾部的元素即可,因为链表尾部的元素就代表最久未被使用的元素。
Redis 实现的是一种近似 LRU 算法,目的是为了更好的节约内存,它的实现方式是在 Redis 的对象结构体中添加一个额外的字段,用于记录此数据的最后一次访问时间。
当 Redis 进行内存淘汰时,会使用随机采样的方式来淘汰数据,它是随机取 5 个值(此值可配置),然后淘汰最久没有使用的那个。
Redis 实现的 LRU 算法的优点:
不用为所有的数据维护一个大链表,节省了空间占用;
不用在每次数据访问时都移动链表项,提升了缓存的性能;
源码实现:在对象头中用 24 字节存储了 key 的最后一次访问时间戳
typedef struct redisObject {
...
// 24 bits,用于记录对象的访问信息
unsigned lru:24;
...
} robj;但是 LRU 算法有一个问题,无法解决缓存污染问题,比如应用一次读取了大量的数据,而这些数据只会被读取这一次,那么这些数据会留存在 Redis 缓存中很长一段时间,造成缓存污染。
4.2.3 Redis LFU
LFU 全称是 Least Frequently Used 翻译为最近最不常用,LFU 算法是根据数据访问次数来淘汰数据的,它的核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。
LFU 算法会记录每个数据的访问次数。当一个数据被再次访问时,就会增加该数据的访问次数。这样就解决了偶尔被访问一次之后,数据留存在缓存中很长一段时间的问题,相比于 LRU 算法也更合理一些。
在 LFU 算法中,Redis对象头的 24 bits 的 lru 字段被分成两段来存储,高 16bit 存储 ldt(Last Decrement Time),低 8bit 存储 logc(Logistic Counter)。

ldt 是用来记录 key 的访问时间戳;
logc 是用来记录 key 的访问频次,它的值越小表示使用频率越低,越容易淘汰,每个新加入的 key 的 logc 初始值为 5。
注意,logc 并不是单纯的访问次数,而是访问频次(访问频率),因为 logc 会随时间推移而衰减的。
在每次 key 被访问时,会先对 logc 做一个衰减操作,衰减的值跟前后访问时间的差距有关系,如果上一次访问的时间与这一次访问的时间差距很大,那么衰减的值就越大,这样实现的 LFU 算法是根据访问频率来淘汰数据的,而不只是访问次数。访问频率需要考虑 key 的访问是多长时间段内发生的。key 的先前访问距离当前时间越长,那么这个 key 的访问频率相应地也就会降低,这样被淘汰的概率也会更大。
对 logc 做完衰减操作后,就开始对 logc 进行增加操作,增加操作并不是单纯的 + 1,而是根据概率增加,如果 logc 越大的 key,它的 logc 就越难再增加。
所以,Redis 在访问 key 时,对于 logc 是这样变化的:
先按照上次访问距离当前的时长,来对 logc 进行衰减;
然后,再按照一定概率增加 logc 的值
剩下 AOF RDB 高可用什么的就没什么劲了,直接看小林Coding 吧……
参考
https://www.cnblogs.com/oxspirt/p/11392437.html
小林 Coding 神!